Quickstart
This page gets you from install to a useful first Atomic session. Atomic is the loop engine for all engineering work: it runs reliable coding-agent loops with stages, tools, artifacts, verification, subagents, review gates, checkpoints, and human approvals.Prerequisites
- Node.js 24 LTS or newer — Atomic requires the latest Node LTS runtime. Check with
node --version. - A package manager — use npm (included with Node), pnpm, Yarn, or Bun. Use Bun 1.3.14+ for Bun installs or workflow-authoring examples.
- Model-provider access — Use
/loginafter startup. Supports provider subscriptions and APIs.
Install
Install the published package globally with npm, pnpm, or Bun: With npm:--ignore-scripts to the install command.
Then start Atomic in the project directory you want it to work on:
Uninstall
Remove the global package with the same package manager you used to install it:~/.atomic/agent/ unless you delete that directory yourself.
Authenticate
Atomic can use subscription providers through/login, or API-key providers through environment variables or the auth file.
Option 1: subscription login
Start Atomic and run:Option 2: API key
Set an API key before launching Atomic:/login and select an API-key provider to store the key in ~/.atomic/agent/auth.json.
See Providers for all supported providers, environment variables, and cloud-provider setup.
First session
On a fresh install with no prior Atomic startup state, Atomic starts with a first-run workflow prompt. Returning users with prior startup state are marked onboarded automatically and continue directly into the normal chat UI; stored credentials by themselves do not skip onboarding. Paste a ticket description, GitHub issue, path to a spec, or task prompt and Atomic hands it to the normal coding-agent session. The handoff raises the selected model to high reasoning when supported and first asks the parent agent to estimate scope from the seed text alone: tickets, issues, and especially specs often list enough work items, files, tests, docs, migrations, or acceptance criteria to classify likely size without immediately inspecting the repo. That text-only pass is treated as a routing confidence signal, not final planning. If the task is clearly tiny/small and high-confidence, the parent can route directly; if the seed references context that must be read or the scope is medium, large, unclear, or risky, it inspects only the necessary issue/spec/path/repo area and can use targeted read-only subagents such ascodebase-locator, codebase-analyzer, and codebase-pattern-finder at their normal defaults. It then chooses goal for focused work or ralph for broader/riskier work, starts the selected workflow, and continues normally. If you paste the task before logging in or selecting a usable model, Atomic keeps only an in-memory copy, asks you to run /login, and resumes with the latest saved task after login or /model selection makes the session ready; /new starts a fresh unresolved onboarding session and drops that saved in-memory task. If you want normal chat instead, type /chat or /chat <message>; other slash commands such as /login, /model, and /atomic still work and do not dismiss onboarding.
Once Atomic starts, the fastest way to get value is to kick off a built-in workflow or invoke a skill. Workflows are the default path for non-trivial tasks and for requests with inherent structure plus a verifiable objective, including implementation, build, debugging, bug-fix, migration, new-feature, scoped multi-file, or docs/code-change work where validation matters. If a prompt says do X until Y, repeat until, iterate until, review/fix until passing, or run checks and fix until green, it already describes a workflow-shaped loop with a stop condition.
Atomic turns repeatable engineering loops into executable stages with inspectable evidence instead of relying on a markdown checklist the model may or may not follow.
For an interactive tour any time, run /atomic inside the TUI; /atomic overview, /atomic workflows, and /atomic example walk through the same flow in more depth.
Try the built-in workflows
Atomic ships with four workflows you can run immediately. Use/workflow list to see them and /workflow inputs <name> to inspect their inputs in your environment.
| Workflow | When to use | Example |
|---|---|---|
deep-research-codebase | Broad, cross-cutting research before you decide what to change. Scout → research-history → parallel specialist waves → aggregator. | /workflow deep-research-codebase prompt="How do payment retries work end to end?" |
goal | Bounded one-off changes when you already know the work surface, exact outcome, and validation — for example bug fixes, debugging, tests, lint/typecheck, docs builds, observable behavior, scoped multi-file edits, or a review/fix/test loop that should continue until passing. Keeps the run focused with a goal ledger, reviewer gates, final status complete, blocked, or needs_human, and optional final-stage PR creation with create_pr=true after approval. | /workflow goal objective="Update the CLI docs for --json, include one example, run the docs build, and finish when the build passes" |
ralph | Planned or broad implementation work from a spec file, GitHub issue, or crisp ticket description, including migrations and new features. Ralph researches as needed, delegates implementation through sub-agents, reviews, records a QA proof video for UI/full-stack changes when practical, iterates until approval or the loop limit, and optionally lets only the final stage attempt PR creation with create_pr=true. | /workflow ralph prompt="Implement specs/2026-03-rate-limit.md and validate burst traffic returns 429" |
open-claude-design | UI and design-system work with separate forked generate and feedback chains; renders a live preview.html you can iterate against. | /workflow open-claude-design prompt="Refresh the settings page hierarchy as a page" |
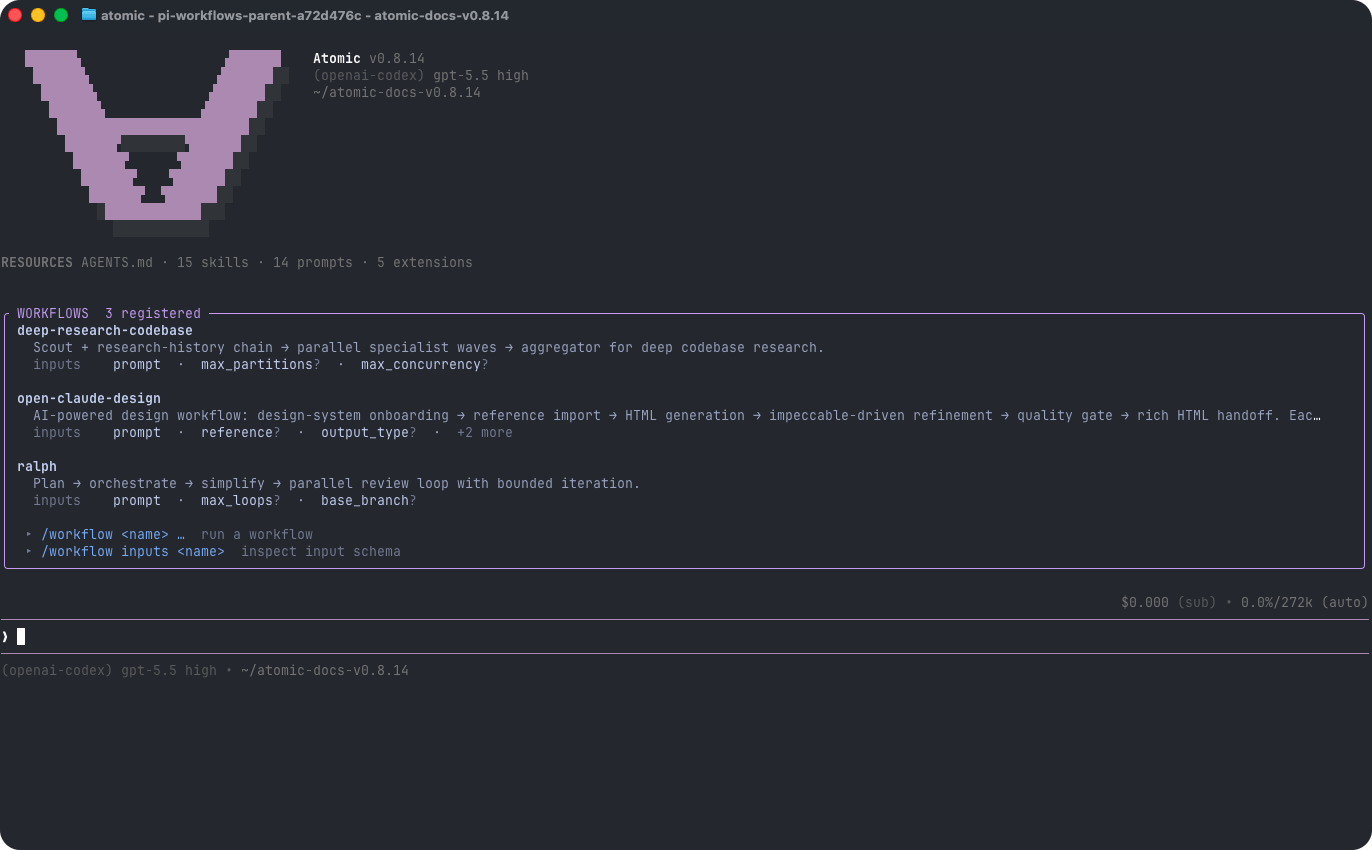
key=value tokens. Values are JSON-parsed when possible, so count=5, flag=true, and objective="multi word value" preserve useful types. Some workflows expose reusable worktree inputs; for example, add git_worktree_dir=../atomic-ralph-wt to ralph to run its stages in a created/reused Git worktree while preserving your current repo-relative cwd. Goal and Ralph skip PR creation by default; prompt text alone does not opt in. Add create_pr=true only when you want the final pull-request stage to inspect provider credentials and attempt provider-appropriate PR/MR/review creation after the workflow’s review gate approves, such as GitHub gh, Azure Repos az repos pr create, or Sapling/Phabricator tooling; the PR-creation instructions live in that final stage. If you call /workflow <name> without required inputs, the TUI opens an inline picker; pass --no-picker to skip it.
You can also launch workflows with natural language — just describe the task in chat and ask Atomic to run the matching workflow:
ralph the default implementation loop after research or spec creation. Give it a spec file, GitHub issue, or crisp ticket description; it refines the prompt, researches as needed, delegates implementation, reviews, records a QA proof video for UI/full-stack changes when practical, and iterates. Add create_pr=true only when you want the final PR handoff after the review gate approves.
For smaller one-off tasks, use goal with a concrete task description that names the work surface, desired outcome, and validation. It is the default for small-to-medium non-trivial changes with verifiable done criteria, especially bug fixes, debugging, scoped multi-file edits, and prompts that say to review/fix, test/fix, or iterate until passing. It keeps the run bounded, captures receipts in a goal ledger, gates completion through reviewers, stops as complete, blocked, or needs_human, and can optionally run only the final PR handoff with create_pr=true after approval.
Monitor and steer a run
Named workflow runs execute in the background. After launch you get a run id; use it to inspect, attach, pause, or resume. First-rungoal/ralph handoffs show the exact /workflow status <run-id> and /workflow connect <run-id> commands in the dispatched card, and you can also ask in the current chat for status or to steer the run at any point.
ctx.ui.input, confirm, select, editor) surface in the graph viewer, not as chat modals — connect to the run to answer them.
Atomic also posts main-chat lifecycle notices when a run completes, fails, or awaits input. If you answer a workflow prompt in the graph or attached stage chat, the main chat receives a display-only answer summary for audit; it does not wake the model, enter LLM context, or answer later prompts. See Workflows for the full reference and authoring guide.
Top skills to invoke directly
Skills are reusable expert instructions. Trigger one with/skill:<name> followed by a request:
| Skill | When to use | Example |
|---|---|---|
research-codebase | Scoped research that writes a grounded artifact for one subsystem or question. | /skill:research-codebase how the rate limiter works in src/middleware/ |
create-spec | Turn research into an implementation-ready plan. | /skill:create-spec from research/docs/2026-03-rate-limit.md |
prompt-engineer | Tighten a vague prompt before a long run. | /skill:prompt-engineer Draft a sharper repo-research prompt for payment retries end to end. |
tdd | Test-first feature or bug work. | /skill:tdd |
impeccable | Critique or refine frontend and product UI. | /skill:impeccable |
playwright-cli | Drive a real browser for end-to-end UI checks, screenshots, and reviewable proof videos. | /skill:playwright-cli |
effective-liteparse | Pull text, tables, or values out of PDF, DOCX, PPTX, XLSX, and image files locally. | /skill:effective-liteparse |
/skill:research-codebase for a focused area and /workflow deep-research-codebase when the answer spans the whole repo. A typical planned flow is /skill:research-codebase → /skill:create-spec → /workflow ralph with the spec path, a GitHub issue, or a crisp ticket description. For smaller one-off tasks, use /workflow goal with a concrete objective that identifies the work surface, states the exact outcome, and names the validation that proves it is done; add create_pr=true only when you want Goal’s final pull-request stage after approval.
Create your own workflow in natural language
You do not have to write TypeScript to add a new workflow. Describe what you want in plain chat and Atomic will design and write it for you using the Workflows reference as the source of truth:- ask clarifying questions if stage purpose, inputs, models, or handoffs are ambiguous,
- write a
.atomic/workflows/<name>.tsdefinition that usesworkflow({ ... })and importsTypefromtypebox, - and run
/workflow reloadso the generated workflow is rediscovered and can be launched with/workflow <name>.
deep-research-codebase, goal, and ralph from @bastani/workflows/builtin.
Default tools and prompts
If you’d rather start with a plain prompt, just type a request and press Enter:read- read filesbash- run shell commandsedit- patch fileswrite- create or overwrite filesfind- discover files by glob patternsearch- search file contentsask_user_question- ask structured questions in the TUItodo- manage file-based todos
find and search in addition to read, bash, edit, and write. Atomic runs in your current working directory and can modify files there. Use git or another checkpointing workflow if you want easy rollback.
Give Atomic project instructions
Atomic loads context files at startup. Add anAGENTS.md file to tell it how to work in a project:
~/.atomic/agent/AGENTS.mdfor global instructionsAGENTS.mdorCLAUDE.mdfrom parent directories and the current directory
/reload, after changing context files.
Common things to try
Reference files
Type@ in any interactive editor, including first-run onboarding, to fuzzy-search files; or pass files on the command line:
Run shell commands
In interactive mode:!!command to run a command without adding its output to the model context.
Switch models
Use/model or CTRL+L to choose a model. Use SHIFT+Tab to cycle thinking level. Use CTRL+P / SHIFT+CTRL+P to cycle through scoped models.
Continue later
Sessions are saved automatically:/resume, /new, /tree, /fork, and /clone to manage sessions.
Non-interactive mode
For one-shot prompts:--mode json for JSON event output or --mode rpc for process integration.
Next steps
- Using Atomic - interactive mode, slash commands, sessions, context files, and CLI reference.
- Workflows - run, inspect, and author multi-stage automation (including the built-in workflows).
- Skills - reusable expert instructions invoked with
/skill:<name>. - Providers - authentication and model setup.
- Settings - global and project configuration.
- Keybindings - shortcuts and customization.
- Atomic Packages - install shared extensions, skills, prompts, and themes.